The retail e-commerce industry is currently bleeding trillions of dollars in global sales to a silent, preventable conversion killer: search abandonment.
According to industry commerce reviews, over 70% of online shoppers will completely abandon a site if their search query returns irrelevant products, and up to 40% will never return. For decades, online retailers attempted to resolve search queries using traditional, keyword-matching databases (such as raw Lucene or standard Elasticsearch). These lexical systems failed. They require rigid, exact syntax matching, forcing merchants to manually manage massive, brittle synonym dictionaries just to map "winter coat" to "heavy parka."
In 2026, the paradigm has fundamentally shifted. Advancements in representation learning and semantic vector spaces have made real-time AI product search an enterprise mandate. Today, instead of forcing users to guess the exact brand names or colors cataloged in a relational database, forward-looking e-commerce brands are engineering custom, self-hosted hybrid search engines.
By mapping products and complex customer intents into the same mathematical vector space, these systems understand conversational context, identify implicit search goals, and match queries like "I need a formal shirt for executive interviews" to the exact, non-obvious silk blazers and custom tailored dress shirts on your digital shelves.
What Is eCommerce Semantic Search?
eCommerce Semantic Search is an intelligent eCommerce search and retrieval framework that analyzes the contextual meaning, user intent, and synonyms behind a shopper's search query rather than simply scanning for matching keyword strings. It operates by converting catalog descriptions and search terms into high-dimensional numerical vectors (embeddings), allowing the search engine to measure mathematical similarity and retrieve conceptually relevant products, even when there are zero shared keywords.
The Keyword Deficit: Why Lexical Search Fails the Modern Shopper
To understand the necessity of semantic search, we must analyze the structural limitations of traditional Lexical (Keyword) Search engines.
Traditional search systems use lexical algorithms like BM25 (Best Matching 25), which ranks documents based on the exact frequency and density of the queried terms within a product's metadata fields. While BM25 is highly performant and exceptionally fast, it remains completely blind to semantic intent:

Lexical search engines suffer from three fundamental architectural flaws:
-
The Synonym Problem: If a user searches for "sneakers" but your catalog describes the item as "athletic footwear," lexical search returns zero results unless a developer has manually mapped those words together in a synonym registry.
-
The Contextual Blind Spot: Lexical systems cannot distinguish between word orders or intents. If a shopper types "phone case with card holder," the system might return standard cardholders or empty phone boxes, failing to isolate the specific hybrid utility item.
-
The Conversational Deficit: When modern users search using natural language or voice queries (e.g., "Show waterproof trekking shoes under six thousand rupees"), lexical parsers break down under the weight of prepositions and comparative adjectives, forcing developers to build brittle, manual filters.
Solving these deficits without destroying performance requires transitioning to a multi-tiered Hybrid Search topology.
The Core Concept: How Semantic Retrieval Operates
At the heart of modern semantic search is the concept of a Vector Embedding.
Imagine a massive, multidimensional virtual warehouse where every product in your inventory is suspended at a specific coordinate based on its physical and conceptual characteristics.
A traditional keyword-based store simply sorts clothes into isolated, labeled boxes. If you ask for a "formal blue shirt," the store manager must go to the "Blue" box and then search for "Formal" labels.
An AI Semantic Search Engine maps your entire inventory into a continuous, high-dimensional mathematical coordinate system (such as a 1536-dimension space). In this space, similar items sit incredibly close to one another.
A navy dress shirt, a steel-blue oxford shirt, and a formal sapphire blazer do not just share tags; their coordinates sit within the exact same mathematical cluster. When a customer types "I need a professional looking top for a corporate meeting," the search engine converts that unstructured sentence into a coordinate, drops a virtual needle at that location, and retrieves the closest physical items sitting around that point (using algorithms like Cosine Similarity or Euclidean Distance).
Technical Comparison: Evaluating eCommerce Search Paradigms
Building a high-converting enterprise portal requires selecting the optimal retrieval methodology:
|
Feature |
Keyword Search (BM25) |
Semantic Search (Vector) |
Hybrid Search (Lexical + Dense) |
|---|---|---|---|
|
Understands Intent |
❌ No |
✅ Yes |
✅ Yes |
|
Handles Synonyms |
❌ No (Requires manual maps) |
✅ Yes |
✅ Yes |
|
Exact SKU Lookup |
✅ Yes (Ultra-precise) |
❌ No (Fuzzy matches only) |
✅ Yes |
|
Conversational Queries |
❌ No |
✅ Yes |
✅ Yes |
|
Best for Enterprise |
❌ No |
❌ No |
✅ Yes (Gold Standard) |
|
Primary Retrieval |
Exact string matching, TF-IDF calculation. |
Mathematical similarity on high-dimensional vectors. |
Parallel execution of lexical and vector pipelines. |
|
Inference Latency |
Ultra-low (Sub-10ms). |
Moderate (30ms - 80ms based on hardware). |
Optimized (30ms - 50ms with parallel queries). |
|
Maintenance Profile |
Low (Standard database indexing). |
High (Embedding generation and scaling). |
Moderate-High (Rank fusion and orchestration). |
Enterprise Adoption: How Retail Giants Leverage Semantic Retrieval
Rather than remaining confined to academic papers, context-aware product retrieval systems are driving billions in incremental revenue for market-leading platforms:
-
Amazon: Leverages deep representation learning models to parse open-ended natural-language shopping queries, matching user context directly with conceptual product categories.
-
Walmart: Integrates a robust, multi-tenant hybrid search pipeline, combining lexical search for precise SKU matching with vector databases to surface matching alternatives across millions of daily active products.
-
Etsy: Utilizes graph-enriched semantic embedding vectors to dramatically improve stylistic, visual, and aesthetic product discovery, allowing long-tail artisan listings to match unique search descriptions.
-
Myntra: Deploys fashion-oriented context vectors capable of executing stylistic conversational commerce (e.g., parsing "boho chic summer outfit" to pull matching sandals, skirts, and accessories from separate departments).
-
Flipkart: Utilizes localized conversational product search nodes, translating complex natural-language inputs across multiple languages and regional syntax boundaries to minimize bounce rates.
Measuring the ROI: Key Business Metrics of Semantic Search
Migrating from a legacy keyword matching engine to an optimized hybrid search platform yields immediate, quantifiable impacts across your core commerce KPIs:
-
Reduced Search Abandonment: Context-aware query routing matches user intent on the first try, reducing search-related exit rates by up to 40%.
-
Higher Conversion Rates: Delivering highly accurate product matches removes cognitive friction, systematically accelerating the user path from search box to checkout confirmation.
-
Increased Average Order Value (AOV): High-fidelity semantic matching supports "Complete the Look" recommendations, naturally presenting complementary accessories that align with the user's primary stylistic purchase goals.
-
Better Product Discovery: Eliminating keyword-dependence unlocks visibility for cold-start catalog listings and un-tagged inventory, maximizing return on warehouse assets.
-
Fewer Zero-Result Searches: Typo correction, phonetic parsing, and synonym mapping ensure the system always returns relevant, high-quality alternatives, eliminating the dreaded "No Results Found" wall.
The Production eCommerce Hybrid Search Pipeline
A production-grade, millisecond-latency e-commerce search system does not rely on a single database query. It coordinates lexical systems, embedding generators, vector index maps, and deep-learning reranking models in a multi-stage execution pipeline.
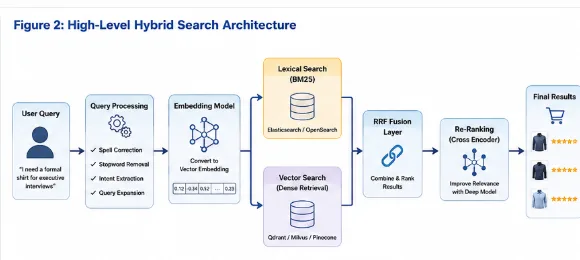
Step-by-Step Architectural Request Flow
Let's break down the execution layers required to run this high-throughput hybrid system in under 50 milliseconds:
1. Query Ingestion and Tokenization
When a user enters a search string, the query passes through an API Gateway to a pre-processing microservice. This service corrects typos, isolates structural values (such as budget thresholds: "under ₹6000"), and parses brand keywords.
2. Dual-Retrieval Path Execution
The processed query is executed across two distinct database indexes simultaneously:
-
The Sparse Path (Lexical): A high-performance search cluster (such as Elasticsearch or OpenSearch) searches the product titles and SKU indexes using standard BM25 algorithms. This guarantees that if a customer types an exact serial number, the correct product is matched instantly.
-
The Dense Path (Semantic): The query is converted into a vector embedding (e.g., using a 384-dimension local model like
bge-small-en-v1.5). A vector database for eCommerce (like PostgreSQL withpgvectoror Qdrant) executes an Approximate Nearest Neighbor (ANN) search on product embedding clusters, capturing conceptually matching inventory.
3. Reciprocal Rank Fusion (RRF)
The two retrieval paths output independent candidate lists. Because lexical scores and vector distance values represent entirely different scales, they cannot be compared directly. The context engine resolves this by applying Reciprocal Rank Fusion (RRF), which assigns a normalized priority score to each product based solely on its relative rank in both output lists.
4. Cross-Encoder Reranking
The top 100 merged candidates are passed to a lightweight Cross-Encoder Reranking Model (such as bge-reranker-large). Unlike bi-encoders, which embed queries and products separately, the cross-encoder analyzes the exact relationship between the search string and the candidate metadata simultaneously, calculating a precise relevance score.
5. API Response Assembly
The top 20 prioritized products are resolved back to catalog metadata databases, enriched with live stock status and pricing layers, and sent to the client browser in a clean, structured JSON format. Connecting these localized product filters to your customer workflows can dramatically lower cart abandonment. Learn how these optimizations shape buyer conversion in our strategic guide on How AI-Powered Customer Support Is Reducing Costs and Improving UX.
Mathematical Modeling: Hybrid Rank Fusion and Semantic Scoring
To calculate absolute relevance scores across disparate lexical and vector indices, production systems use dynamic, non-linear scoring math.

Tooling and Infrastructure for Enterprise Semantic Search
Building a reliable, sub-second hybrid search gateway requires integrating multiple database systems and vector routing layers:
|
Tool / Framework |
Primary Role in Search |
Why It Is Chosen |
|---|---|---|
|
Qdrant / Milvus |
High-performance vector database hosting. |
Optimized HNSW indexes that handle millions of vector coordinates with sub-30ms latencies. |
|
PostgreSQL (pgvector) |
Relational vector storing and unified inventory mapping. |
Ideal for small-to-mid catalogs, allowing teams to query relational metadata and vector embeddings in a single SQL statement. |
|
Cohere Rerank / BGE |
Contextual Cross-Encoder reranking. |
Turns raw coordinate matches into highly precise, conversion-optimized recommendations. |
|
Elasticsearch / OpenSearch |
Sparse BM25 lexical catalog search. |
Industry standard for tokenization, fuzzy text matching, and enterprise faceting. |
|
Model Context Protocol (MCP) |
Standardizing product APIs for conversational agents. |
Ensures shopping assistants can securely query catalog parameters using pre-defined API boundaries. |
To evaluate whether your organization should engineer this high-performance search node internally or lease a standard third-party software license, review our complete technical roadmap: Custom Software Development vs SaaS: When Businesses Should Build Instead of Buy.
Case Study: "OmniRetail Co." Hybrid Search Transformation (Hypothetical)
The following case study represents an illustrative, hypothetical scenario model designed to demonstrate real-world systems engineering topologies.
-
Business Problem: A major multi-category online retailer with over 150,000 active SKUs suffered from a 26% search abandonment rate. Customers routinely left the platform after searches like "protective outdoor gear" returned zero results due to exact tag mismatches.
-
Existing Challenges: Their legacy database relied on keyword matching over static product titles. Attempts to fix the issue using manual synonym registries on Elasticsearch created a maintenance bottleneck, costing over $14,000 monthly in manual development hours.
-
Solution Architecture: TechMamba engineered a private, unified Hybrid Search pipeline running on AWS. Product catalogs were embedded into a high-performance Qdrant cluster in parallel with their relational databases. Every query was processed using Reciprocal Rank Fusion ($RRF$) combined with a specialized BGE reranker.
-
Results Achieved: Within 90 days of deployment, search abandonment dropped from 26% to 8.4%, digital purchase conversions increased by 19.3%, and the engineering team completely eliminated manual synonym updates. This dramatic efficiency gain highlights how modern search optimizations directly maximize e-commerce operating margins.
Security, Privacy, and Data Governance in Conversational Search
When customers use natural language search, they often share sensitive personal context (e.g., searching for medical items: "creams for severe diabetic eczema"). If your search pipeline caches, leaks, or transmits these search query details to public models, your enterprise faces severe data protection liabilities under GDPR and CCPA.
Zero-Trust Semantic Ingestion
To ensure absolute compliance, your search gateway must sanitize query inputs at the perimeter. Raw text must pass through a local, stateless sanitation microservice that scrubs potential Personally Identifiable Information (PII) before vector embeddings are generated or passed to external model endpoints.
To see how these defensive perimeters are designed to shield LLMs and internal vector databases from malicious data leakage or prompt injections, explore our detailed systems guide: Enterprise AI Security in 2026: Protecting LLMs, Data, and Business Workflows.
Mitigating Search Abuse
Furthermore, because semantic search gateways accept open-ended natural language inputs, they can be targeted by prompt injection exploits designed to extract wholesale database catalogs. Enforcing strict, schema-validated routing boundaries using standard communication layers like the Model Context Protocol (MCP) prevents models from executing unapproved database scripts, ensuring your internal data remains completely secure.
Ensure these boundaries align with global compliance mandates by reviewing our architectural framework: AI Governance Explained: Building Responsible Enterprise AI Systems in 2026.
Actionable Implementation Checklist
To build and scale your custom semantic search system successfully, follow this structured development roadmap:
-
[ ] Establish Search Latency Budgets: Set strict performance limits for your query paths (e.g., target <15ms for retrieval, <35ms for reranking).
-
[ ] Parse Catalogs Semantically: Generate dense product embeddings using specialized local models like
bge-large-en-v1.5. -
[ ] Enforce Metadata Partitioning: Map role-based security tags to your vector clusters to prevent unauthorized product access.
-
[ ] Deploy Hybrid Indices: Configure parallel search execution across sparse BM25 and dense vector database nodes.
-
[ ] Implement Reciprocal Rank Fusion: Configure RRF matching values ($k = 60$) to merge lexical and vector search outputs.
-
[ ] Integrate Cross-Encoder Rerankers: Set up lightweight reranking microservices to prioritize candidate lists before client delivery.
-
[ ] Enable Context Prefix Caching: Structure search queries deterministically to maximize GPU memory cache performance.
-
[ ] Monitor Query Telemetry: Track search performance, semantic drift, and search abandonment metrics using tracing software like Langfuse.
Expert Opinion: Why Search is the Ultimate High-Volume AI Interface
Many software engineering teams treat artificial intelligence as a superficial chat bubble. This is a complete failure of systems design.
The most effective, high-leverage interface for enterprise AI is not a free-form chat prompt—it is the search bar.
When a user searches for a product, they are explicitly declaring their current intent. By utilizing hybrid vector search, context-optimized prompts, and high-performance reranking models, you convert a simple text entry box into an intelligent sales assistant that understands the customer, matches their exact needs, and dynamically optimizes your conversions.
The future of digital commerce belongs to brands that treat search space as a premium, high-density contextual environment. By building secure, self-hosted semantic search pipelines, you transform raw generative models into precise, highly efficient operational assets that scale transaction values and systematically eliminate search abandonment liabilities.
To see how optimizing these backend transaction layers directly lowers operational overhead and shapes modern digital customer behavior, read our complete guide: Why Small Businesses Are Switching to AI Automation in 2026.
Scale Your Custom Visual AI Architecture with TechMamba
Designing, hosting, and optimizing a high-performance, secure semantic search gateway requires extensive, real-world machine learning experience. At TechMamba, we specialize in building highly secure private assistant networks, performant computer vision pipelines, and automated multi-agent environments designed to protect your operational margins and scale your enterprise efficiency.