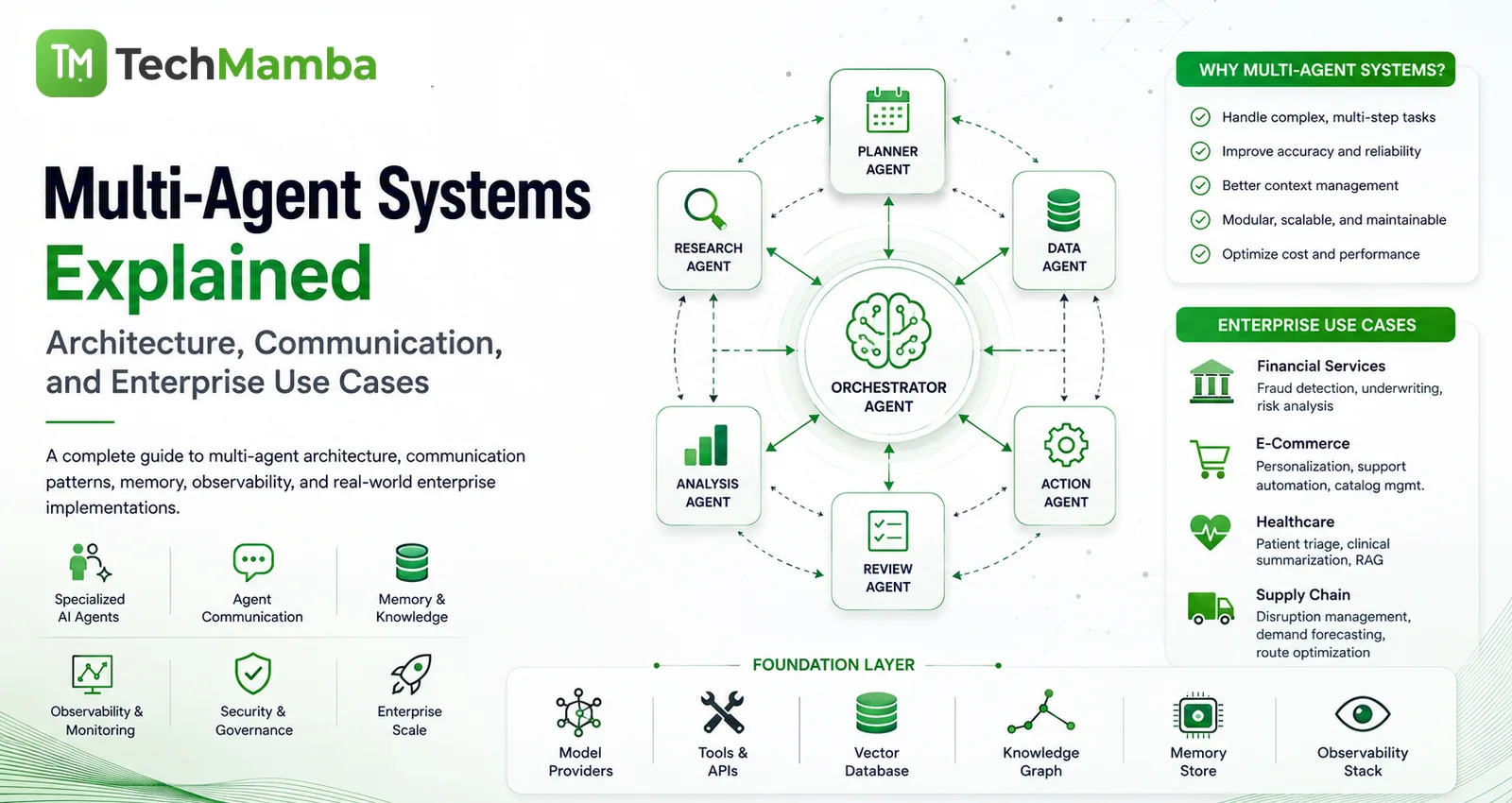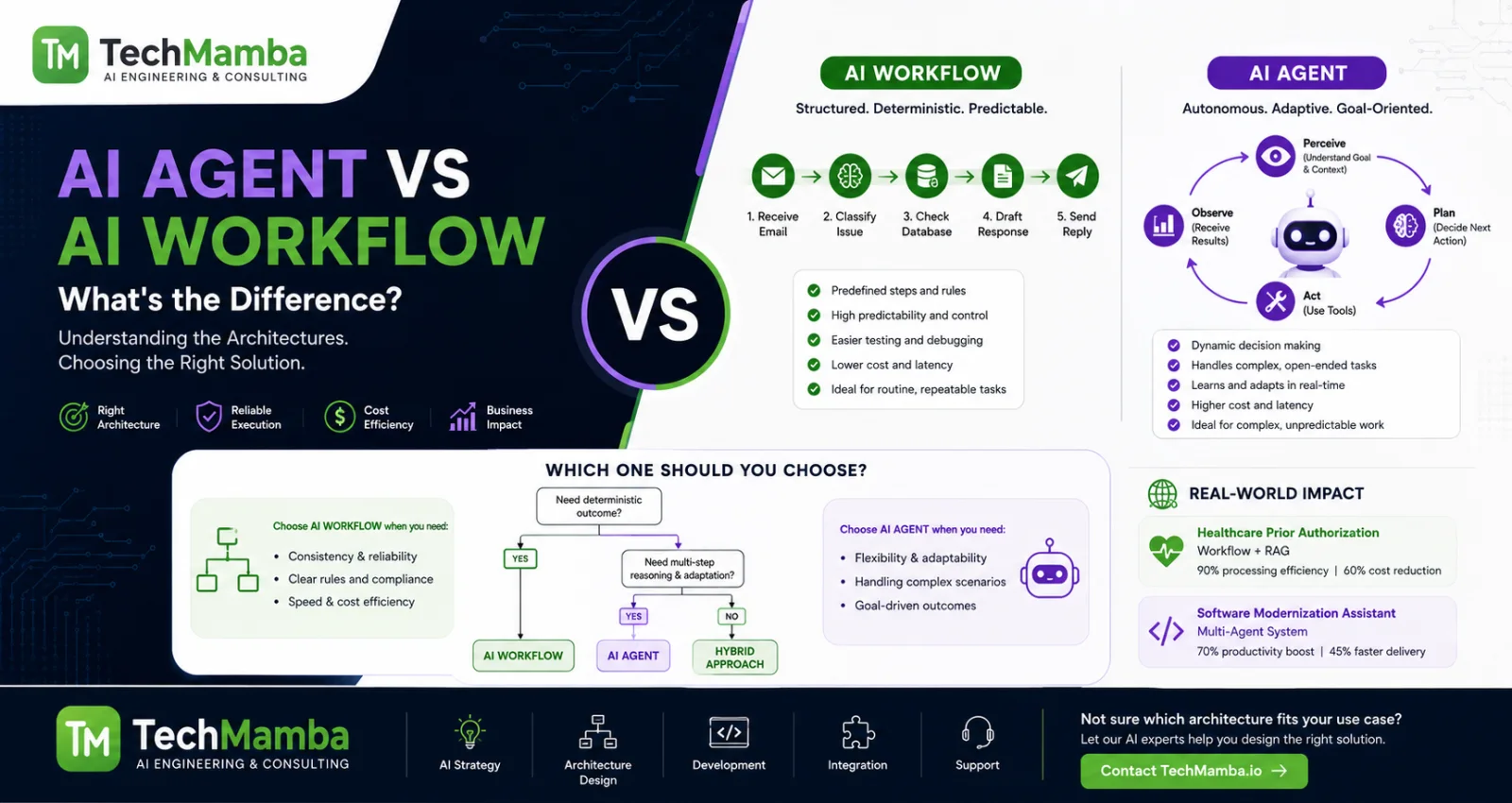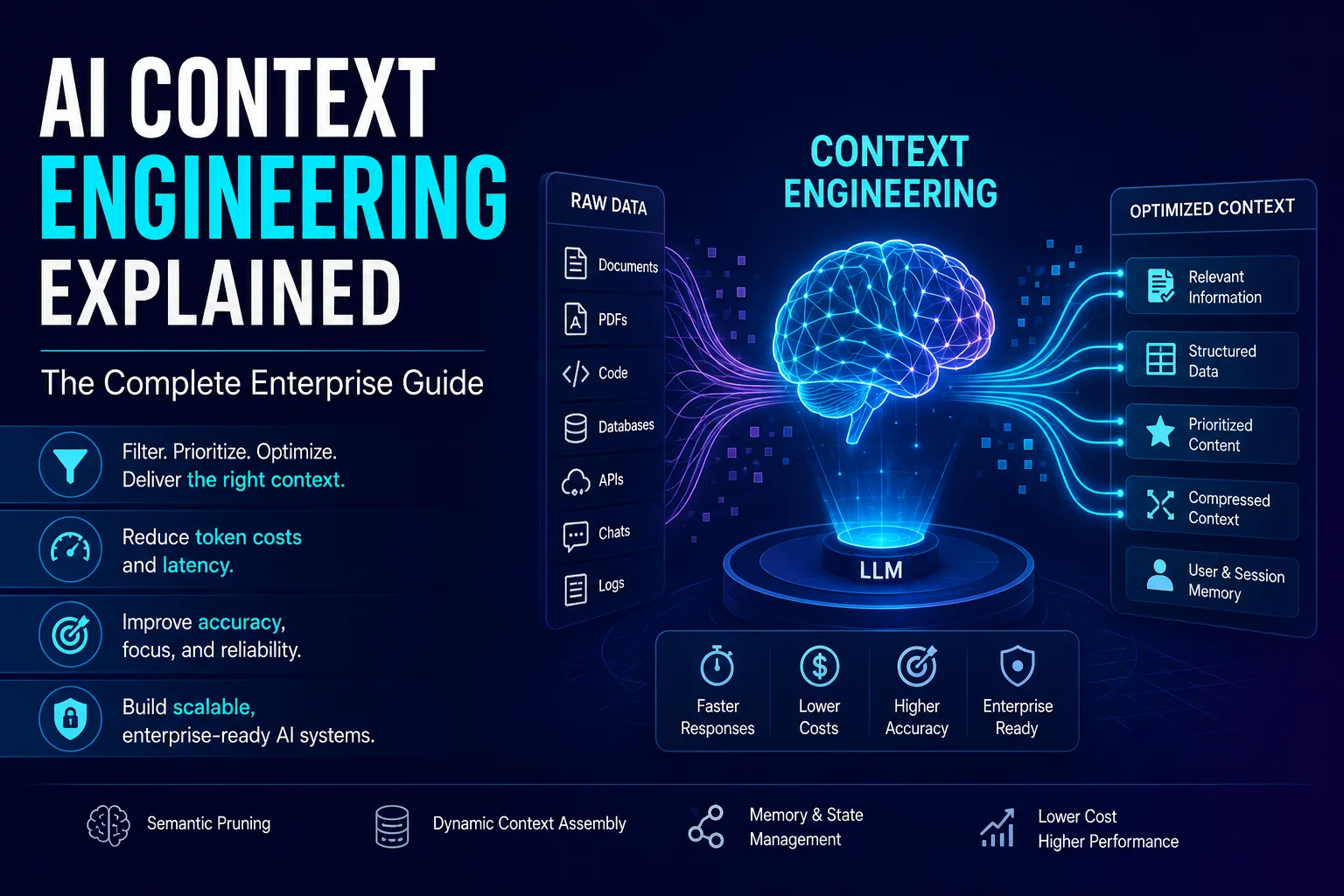
The software industry is currently experiencing a dangerous architectural delusion: the belief that massive context windows—scaling from 200,000 to over two million tokens in modern long context LLMs—have rendered data optimization obsolete.
Engineering teams, swept up in the marketing promise of "just dump the entire codebase or PDF directory into the prompt," are deploying enterprise AI applications that suffer from crippling latency spikes, runaway operational costs, and catastrophic reasoning failures.
In production environments, context size does not equal cognitive accuracy. Loading an unstructured data dump into an LLM context window is the modern systems equivalent of a severe memory leak. It dilutes the model’s attention, increases retrieval noise, and triggers a massive financial "context tax" on every single user transaction.
To build reliable, scalable, and cost-effective AI systems, enterprises must transition from basic prompt writing to AI Context Engineering. This is the rigorous software engineering discipline of dynamically selecting, compressing, structuring, and routing information to present an LLM with the absolute minimum, highest-value payload required to execute a specific task.
What Is AI Context Engineering?
AI context engineering is the programmatic, system-level discipline of managing, filtering, and optimizing the input payloads (prompts, retrieved files, system instructions, and state history) sent to large language models. Rather than relying on massive, unoptimized context windows, context engineering uses techniques like semantic pruning, token budget routing, metadata partitioning, and dynamic prompt compression to maximize reasoning accuracy while reducing latency and inference costs.
The Core Concept: Why Context Management Matters
To understand context management, think of a large language model like an incredibly brilliant, temporary consultant hired to audit your firm.
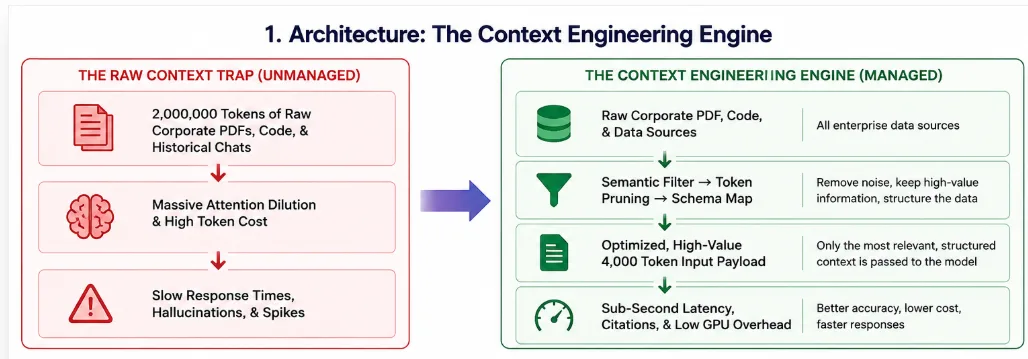
If you hand this consultant a chaotic, unorganized stack of 10,000 unindexed corporate PDFs, raw database logs, and random historical chats, they will spend 95% of their billable hours sorting through garbage, getting distracted by irrelevant footnotes, and ultimately delivering a generic, inaccurate summary.
If, instead, an organized manager hands this consultant a single, highly structured, 2-page briefing document containing the exact three metrics and five clauses needed to solve the current problem, the consultant will deliver an flawless analysis in seconds.
AI Context Engineering is that organized manager. It acts as an intelligent abstraction layer between raw corporate data stores (databases, vector indices, document hubs) and the core inference engine.
By filtering out irrelevant semantic noise before a query reaches the model, context engineering preserves the model's focus. It represents a fundamental shift from treating LLMs as raw data storage units to treating them as execution engines.
Prompt Engineering vs. Context Engineering
It is common to confuse prompt engineering with context engineering, but they operate at entirely different scales:
|
Dimension |
Prompt Engineering |
AI Context Engineering |
|---|---|---|
|
Primary Objective |
Writing better instructions, personas, and system guidelines. |
Programmatically optimizing the entire data payload. |
|
Operational Scope |
Single prompt template. |
Entire enterprise AI data pipeline. |
|
Methodology |
Manual drafting, word-smithing, and styling. |
Automated semantic pruning, RAG routing, and dynamic memory. |
|
Systems Integration |
Static file templates. |
Dynamic database queries, API schemas, and state updates. |
|
Primary Metric |
Output formatting and behavioral alignment. |
Latency reduction, token cost efficiency, and accuracy. |
Where prompt engineering focuses on how the model is instructed, context engineering governs what data the model is allowed to see.
The Illusion of Unlimited Context Windows: Attention Dilution
To understand why programmatic context window optimization is mandatory, we must examine the underlying mechanics of Transformer models.
When an LLM processes an input, its self-attention mechanism calculates mathematical relationships between every token in the sequence. This operation has a computational complexity of $O(L^2)$, where $L$ represents the sequence length.
While architectural optimizations like FlashAttention and Grouped-Query Attention (GQA) have mitigated the physical memory bottlenecks of large sequences, they do not solve the cognitive limitation known as Attention Dilution.
The "Lost in the Middle" Phenomenon
An LLM’s ability to retrieve information from its context window is not uniform. The model exhibits significantly higher retrieval accuracy at the absolute beginning (pre-fill bias) and absolute end (recency bias) of the input sequence.
When critical grounding facts are positioned in the middle 60% of a massive prompt, retrieval accuracy degrades sharply. This is the "lost in the middle" effect.
The Three Core Pillars of Context Orchestration
A production-grade context engineering framework operates across three foundational layers:
-
Semantic Pruning and Token Compression: This layer uses mathematical and structural rules to remove conversational noise, duplicate records, and uninformative tokens from the context envelope. Instead of passing raw text, files are parsed into high-density semantic structures. Using specialized compression pipelines, we can reduce input payloads by up to 80% while retaining 98% of the core reasoning capacity.
-
Dynamic Context Assembly: This layer programmatically constructs the prompt using strict database schemas, JSON payloads, and dynamic ordering rules. Rather than relying on static prompt templates, a context assembler constructs the prompt on the fly based on the user's authenticated directory parameters, the semantic classification of the query, and real-time database inputs.
-
Active State and Refreshment (AI Memory): For multi-agent systems and multi-turn conversational agents, the context engine must manage conversational AI memory dynamically. Instead of appending the entire chat history to every request (which rapidly inflates costs), the active memory layer summarizes historical interactions, maintains state vectors, and prunes older conversations once their immediate contextual value has expired.
Enterprise Context Engineering in Practice
Context engineering must be designed to address the specific data formats, regulatory bounds, and performance requirements of your target industry:
-
Healthcare Providers Synthesizing Patient Records: Clinical diagnostic applications must compile decades of medical history, lab results, and pharmacy charts. Instead of dumping raw records, a clinical context engine groups data by therapeutic relevance, filters out redundant baseline visits, and dynamically ranks diagnostic notes based on the current medical query. This ensures HIPAA compliance while giving the model a clear, structured patient overview.
-
Financial Institutions Underwriting Mortgages: Credit scoring models require access to tax records, employment histories, and external banking ledgers. The context layer enforces strict document-level permissions, stripping out restricted identifiers (PII) before the token payload is constructed. This prevents bias and ensures full regulatory compliance, which is a major concern when designing an Enterprise AI Governance framework.
-
SaaS Engineering Platforms Debugging Log Files: Real-time log monitors process gigabytes of system events. The context layer compresses verbose stack traces into unique pattern signatures, passing only the anomaly vectors to the model. This is critical when building systems designed to manage high transactional throughput while keeping AI Agent Development Costs within budget.
-
E-commerce Customer Support Platforms Routing Refunds: E-commerce agents require access to customer orders, shipping tracking details, and inventory systems. The context engine dynamically gathers these variables using standardized communication APIs, ensuring the assistant operates with absolute factual precision. See how these integrated customer workflows lower operational friction in our guide on How AI-Powered Customer Support Is Reducing Costs and Improving UX.
The Enterprise AI Tooling Landscape
Building a performant context gateway requires integrating multiple specialized open-source and infrastructure tools:
|
Tool |
Primary Role |
When to Use |
|---|---|---|
|
LangGraph |
Multi-agent state orchestration. |
When you need to manage complex, cyclic agent interaction flows. |
|
LlamaIndex |
Context retrieval and ingestion. |
When querying multi-format enterprise files (PDFs, SQL databases, wikis). |
|
LLMLingua |
Programmatic prompt compression. |
To reduce raw input payloads by up to 80% before LLM processing. |
|
pgvector |
Metadata-filtered vector storage. |
To enforce Role-Based Access Control (RBAC) during semantic searches. |
|
Redis |
High-speed semantic caching & AI memory. |
For lightning-fast retrieval of conversational state and common queries. |
|
vLLM |
Efficient inference and prefix caching. |
To cache long static context blocks directly within GPU memory. |
Hypothetical Case Studies: Context Orchestration in Action
The following case studies represent illustrative, hypothetical scenario models designed to demonstrate real-world systems engineering topologies.
Case Study 1: Global Fintech "Acuity Wealth" (Hypothetical)
-
Business Problem: Institutional wealth advisory portal requiring automatic generation of portfolio compliance summaries from massive, 100-page SEC PDF files.
-
Existing Challenges: Loading full SEC filings into model prompts resulted in average response latency exceeding 14 seconds, monthly API costs scaling past $34,000, and frequent balance sheet hallucinations due to the "lost in the middle" effect.
-
Solution Architecture: TechMamba engineered a decoupled, dynamic context pipeline.
-
Technologies Involved: LangGraph orchestration, PostgreSQL with
pgvectorfor metadata partitioning, LLMLingua microservices, and vLLM running on AWS. -
Why This Architecture Was Chosen: Separating retrieval, compression, and inference allowed the team to filter out up to 80% of redundant legal clauses before passing the prompt to the core model, protecting performance and ensuring high-density context.
-
Results Achieved: Average latency fell by 78% (from 14.2 seconds to 3.1 seconds), monthly token billing dropped by 72% (saving over $24,000 per month), and factual accuracy achieved 99.4%, eliminating hallucinations.
Case Study 2: "Aegis Medisystems" (Hypothetical)
-
Business Problem: Matching patient Electronic Health Records (EHRs) with active, hyper-specific oncology clinical trial parameters.
-
Existing Challenges: HIPAA compliance blocked sending raw, unredacted patient medical histories to public model endpoints. Furthermore, EHRs contain significant formatting noise, duplicates, and redundant billing tables that diluted model focus, causing matching errors.
-
Solution Architecture: We engineered a hardened, zero-egress context gateway running within Aegis's private cloud network.
-
Technologies Involved: Quantized Llama-3-70B on vLLM, custom spaCy Named Entity Recognition (NER) pipeline for PII scrubbing, and Docker sandboxes.
-
Why This Architecture Was Chosen: Hosting quantized open-weight models on a secure Private AI Assistant infrastructure ensured zero data leakage. Running a localized NER pre-processing layer sanitized all protected health information (PHI) before vectorization occurred.
-
Results Achieved: Complete regulatory HIPAA alignment with zero external data transmissions, a 41% increase in medical trial matching accuracy, and a 2x increase in transaction throughput.
Actionable Implementation Checklist
To build and scale your context engine successfully, follow this structured development roadmap:
-
[ ] Define Token Budgets: Establish strict token-limit thresholds for every unique user query path.
-
[ ] Chunk Documents Semantically: Avoid static character splits; parse files by logical headings or Markdown structures.
-
[ ] Implement Metadata Partitioning: Enforce row-level security tags at the vector database level.
-
[ ] Deploy Reranking Models: Use Cohere or BGE-Reranker to prioritize the top 5 most relevant context chunks.
-
[ ] Run Prompt Compression: Integrate LLMLingua to strip uninformative tokens from retrieved contexts.
-
[ ] Enable Prefix Caching: Structure prompts deterministically (static blocks first) to maximize GPU cache hits.
-
[ ] Monitor Real-Time Latency: Trace pre-fill vs. decoding latency using professional telemetry tools.
-
[ ] Evaluate Faithfulness: Deploy automated checks to verify generated outputs match retrieved source chunks.
Designing a High-Throughput Context Pipeline
A robust enterprise context pipeline is decoupled from the main database layer. It operates inside a secure middleware pipeline, transforming raw queries and external database outputs into highly optimized token packages.
Managing Token Budgets with Prompt Caching
Modern inference serving engines (such as vLLM and TensorRT-LLM) implement Prefix Caching. This allows the serving engine to cache the KV (Key-Value) states of the initial, static portions of your prompts (like system instructions and long reference documents) inside GPU memory.
To take advantage of prefix caching, your context pipeline must be deterministic. The static, long-lived instructions must be positioned at the absolute beginning of the prompt and remain identical across transactions. By structuring prompts in this exact sequence, you can achieve up to a 90% reduction in pre-fill latency and slash GPU computing overhead. Learn how to align your system configurations with these hardware optimizations in our deep-dive on LLM Inference Optimization.
Advanced Mathematical Modeling (Optional Deep-Dive)
To scale context pipelines programmatically, your engineering team must measure the relationship between prompt length, information density, and model reasoning performance.
We model this relationship using the Attention Dilution Index ($ADI$) and the Token Compression Ratio ($TCR$).
1. The Attention Dilution Index
We calculate the concentration of attention weights across the prompt window to identify if the model's focus is being dispersed by unnecessary text. Let the attention weights for each token in an input sequence of length be represented by:

A high $ADI$ indicates that the model's focus is spread flatly across too many uninformative tokens (semantic noise), increasing the probability of reasoning errors and hallucinations. An optimized context engine actively filters input vectors to concentrate attention weights, driving the lower.
2. The Token Compression Ratio ($TCR$)

In standard enterprise environments, our context engines achieve, translating to a 75% reduction in ongoing token costs without degrading task execution performance. This metric is a foundational requirement when monitoring scaling software overhead, as tracked by production AI Observability systems.
The Ultimate Integration: Security, Governance, and Context
To run a reliable enterprise AI ecosystem, you cannot view these disciplines in isolation. They are structurally connected:
Without an optimized context engine, your security guardrails will experience high latency overhead, and your compliance audits will remain blind to hidden prompt injections. Integrating an optimized context pipeline with a secure Agentic RAG or standard RAG Architecture creates an impenetrable perimeter around your digital assets.
Expert Opinion: What Most CTOs Get Wrong
Many technical leaders assume that the rapid drop in raw API token pricing has made context optimization irrelevant. This is a severe misunderstanding of systems engineering.
While token prices continue to decline, the cognitive tax of raw, unoptimized data inputs remains completely unchanged. If you present an LLM with a 100,000-token input containing 95,000 tokens of redundant metadata and formatting clutter, the model’s reasoning capacity will degrade. It will focus on irrelevant patterns, lose the primary user intent, and output generic, low-value responses.
The future of enterprise AI isn't about giving models more data—it's about giving them the right data at the right time. By treating prompt space as a premium, high-density memory buffer, you turn your language models into precise, highly efficient operational assets.
Optimize Your Enterprise Infrastructure with TechMamba
Designing, hosting, and optimizing a performant context gateway requires extensive, real-world systems engineering experience. At TechMamba, we specialize in building highly secure private assistant networks, performant context compression pipelines, and automated multi-agent environments designed to protect your operational margins and scale your enterprise efficiency.
If you are evaluating custom platform development versus off-the-shelf subscriptions, calculate how technical optimization margins factor into your long-term success. Read our analysis in Custom Software Development vs SaaS: When Businesses Should Build Instead of Buy.
-
-