
If your enterprise security team is currently approving the deployment of public SaaS AI interfaces for internal corporate operations, you are likely opening your infrastructure to significant data leakage risks.
In 2026, the initial rush to adopt out-of-the-box AI wrappers has met the hard reality of compliance, data sovereignty, and strict IP protection. While general consumer models are excellent for surface-level brainstorming, they fail completely when exposed to regulated corporate datasets (such as HIPAA-covered patient records, SOC2-protected financial profiles, or proprietary source code).
Deploying a Private AI Assistant inside a secure, sandboxed enterprise perimeter is no longer just an optimization strategy—it is a mandatory security baseline.
Before tasking your development team with spinning up a basic open-source model, you need a hardened, production-ready blueprint. This guide covers the end-to-end engineering architecture, data-level permissioning, and hosting practices required to build an isolated, highly performant private assistant.
What Is a Private AI Assistant?
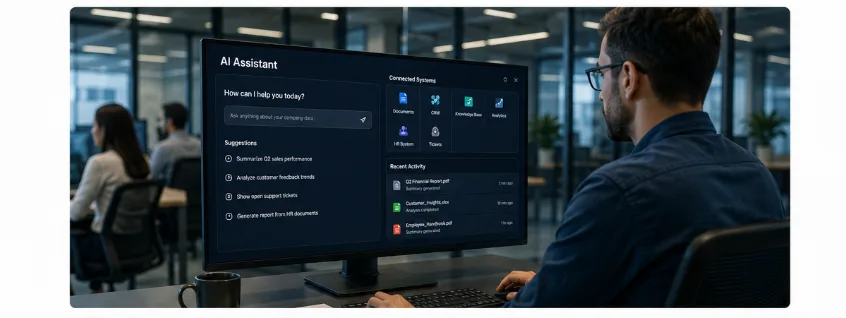
A private AI assistant is a secure enterprise AI system that combines large language models, Retrieval-Augmented Generation (RAG), vector databases, role-based access controls, workflow automation, and enterprise integrations to provide employees with accurate access to company knowledge without exposing sensitive business data.
Unlike public AI tools, private assistants operate within controlled environments, respect organizational permissions, and can securely interact with internal applications such as CRMs, ERPs, knowledge bases, and document repositories.
The Anatomy of an Enterprise-Grade Private AI Architecture
A secure private AI platform is fundamentally decoupled. It separates the presentation interface, the orchestration logic, and the raw computational inference engines into independent, isolated microservices.
Below is the production-grade private deployment:
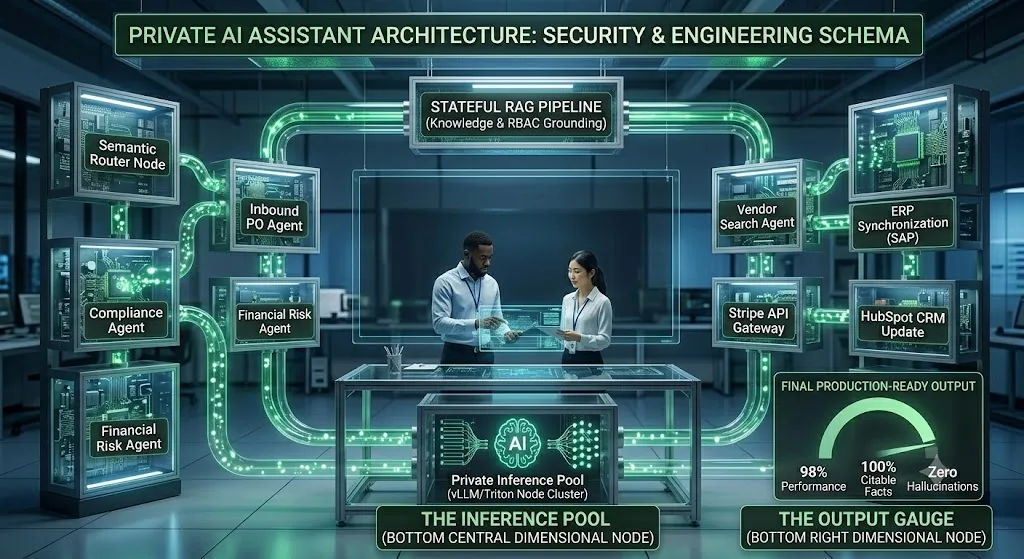
By decoupling these services inside an isolated Virtual Private Cloud (VPC), you ensure that no raw token, system prompt, or user context payload ever leaves your controlled cloud network boundary.
1. The Identity & Access Control Layer (The Security Core)
The single biggest failure of public AI chatbots in enterprise settings is their lack of database permission awareness. If you index your entire company wiki into a single vector database, a junior employee can simply ask the assistant: "What is the executive compensation packages sheet?" and the model will confidently retrieve the unauthorized context.
Why Organizations Are Moving Toward Private AI Assistants
The rapid adoption of public AI tools created a new challenge for enterprise organizations.
Employees quickly discovered how useful generative AI could be for writing reports, summarizing information, and answering questions. However, security and compliance teams soon identified significant risks surrounding sensitive data exposure, access control, and governance.
Organizations today require AI systems that can:
- Access internal company knowledge
- Respect existing security permissions
- Maintain audit trails
- Operate within compliance requirements
- Integrate with existing software ecosystems
This shift is driving the adoption of private AI architectures that combine language models with enterprise-grade security controls.
For organizations evaluating why public AI tools alone are insufficient, read our detailed analysis: Why ChatGPT Alone Is Not Enough for Enterprise AI.
Which Businesses Benefit Most from Private AI Assistants?
Private AI assistants create the highest value in organizations where employees spend significant time searching for information, navigating complex systems, or handling sensitive data.
Examples include:
- Financial Services
- Healthcare Organizations
- Manufacturing Enterprises
- Logistics Companies
- SaaS Businesses
- Legal Firms
- Professional Services Organizations
For these organizations, private AI assistants reduce information silos, improve productivity, and help employees make decisions faster while maintaining strict security controls.
Federated Authentication (OIDC & SAML)
Your API gateway must intercept every incoming request to validate JWT (JSON Web Tokens) generated by platforms like Okta, Azure AD, or Ping Identity. This verifies who the user is before any semantic query processing begins.
Document-Level Metadata Partitioning (RBAC at the Vector Layer)
When constructing your Retrieval-Augmented Generation (RAG) document pipeline, you must never store flat data chunks without active security tags.
2. Guardrails and LLM Firewalls: Preventing Prompt Injections
A private assistant connected to internal databases via tool-calling is vulnerable to prompt injection attacks if left unprotected. An adversary could input malicious instructions hidden inside database entries or user profiles to trick the assistant into bypassing safety systems or dumping its system prompts.
We implement a two-tiered semantic firewall system:
Inbound Guardrails (Input Sanitation)
Before a user query is sent to the orchestration engine, a lightweight local model (such as Llama Guard) scans the input string for payload injections, toxic instructions, or attempts to access system-level configuration parameters. Additionally, regular-expression-based microservices scrub potential PII (Personally Identifiable Information) like Social Security numbers or credit card sequences.
Outbound Evaluation (Alignment Verification)
When the core language model generates a response, it passes through an automated validation layer (such as NeMo Guardrails) to check against predefined business boundaries. This verifies that the response contains factual citations derived exclusively from your vector index, completely eliminating untraceable hallucinations.
3. High-Performance Hosting: Private Cloud vs. On-Premise GPU Nodes
Determining where to host your core inference engine is a critical exercise in balancing latency, compliance requirements, and ongoing infrastructure costs.
Option A: Isolated Private Cloud (AWS, Azure, GCP)
For most mid-to-large enterprises, running custom containerized models within private VPC infrastructure is the optimal choice. Platforms like AWS Bedrock (Private Endpoints) or dedicated Kubernetes clusters (EKS) running specialized frameworks like vLLM allow you to scale resources dynamically.
-
Why vLLM is favored: vLLM implements PagedAttention, which drastically optimizes GPU memory usage during high concurrent user traffic. This reduces your required active GPU footprint (like Nvidia A100s or H100s) and cuts cloud hosting expenses by up to 50% compared to unoptimized setups.
Option B: Local On-Premise Compute (Bare Metal GPU Racks)
For highly regulated industries (such as defense, government contracting, or specialized healthcare), complete physical data isolation is mandatory.
-
The Engineering Reality: Hosting open-weight frontier models (such as Llama 3.1 70B/8B or Mistral Large) on physical hardware inside your local server rooms completely eliminates third-party data processing risks. However, it requires significant upfront capital investments (CAPEX) for GPU procurement and dedicated DevOps talent to manage physical clustering, load-balancing, and container provisioning.
RAG vs. Parametric Tuning for Private Assistants
To keep your private assistant highly performant and cost-effective, you must choose the correct customization methodology for each distinct operational workflow:
-
Use RAG for Contextual Knowledge: To make your assistant an expert on dynamic files (policies, codebases, invoice tracking, or HR benefits), implement a high-performing semantic vector search. Do not waste expensive compute cycles trying to fine-tune a model to memorize files; it is slower, prone to factual errors, and offers zero document-level access controls.
-
Use Parameter-Efficient Fine-Tuning (PEFT/LoRA) for Style and Syntax: If your private assistant must output clean database files matching complex proprietary schemas, speak in a highly technical brand voice, or execute specialized code logic, fine-tune a smaller open-source model. This keeps your system prompts incredibly short and fast, minimizing your ongoing computing costs. Learn how to map this operational tradeoff in our deep-dive comparison: RAG vs. Fine-Tuning in 2026: An Architecture-First Guide.
Real-World Enterprise Examples
Many organizations are already moving toward private AI architectures.
Financial Services
Large financial institutions use internal AI assistants to help advisors search research documents, compliance materials, and customer information while maintaining strict access controls.
Healthcare Organizations
Healthcare providers are deploying private assistants to help clinicians retrieve treatment guidelines, patient documentation, and operational procedures while protecting sensitive medical records.
Manufacturing Enterprises
Manufacturing companies use private AI systems to assist engineers with technical documentation, maintenance procedures, and operational knowledge spread across multiple systems.
These deployments demonstrate that enterprise AI success depends less on the language model itself and more on the surrounding architecture, governance, and data controls.
How Private AI Assistants Reduce AI Hallucinations
One of the biggest concerns surrounding enterprise AI is hallucination—the generation of inaccurate or fabricated information.
Private AI assistants reduce this risk by grounding responses in trusted enterprise knowledge rather than relying solely on model memory.
Modern enterprise deployments typically combine:
- Retrieval-Augmented Generation (RAG)
- Source attribution
- Semantic search
- Confidence scoring
- Output validation layers
This ensures that responses are based on approved company knowledge rather than assumptions generated by the model.
Organizations looking to improve AI reliability should focus on retrieval quality, governance controls, and knowledge management before investing in larger models.
For a deeper technical explanation, read RAG Architecture Explained: A Complete Guide for Enterprises.
Technical Comparison: Private Assistant vs. Public SaaS Wrapper
|
Operational Metric |
Public SaaS API (e.g., ChatGPT Plus) |
Private Self-Hosted Assistant |
|---|---|---|
|
Data Privacy & Training Isolation |
High Risk (Your data can be ingested for public training). |
Absolute (Your data never leaves your secure private VPC). |
|
Enterprise Directory Integration |
Extremely Limited (Lacks deep OIDC/RBAC synchronization). |
Native (Document-level vector permission filtering). |
|
Workflow Interoperability |
Rigid (Limited to superficial, text-only chat bubbles). |
Unlimited (Secure API access to write to CRMs, databases). |
|
Cost Scaling Predictability |
High Linear OPEX ($20+ per seat, per month). |
Fixed, Scalable CAPEX/OPEX based on direct GPU compute. |
|
Edge-Case Safety Guardrails |
Third-party managed; highly volatile system prompt shifts. |
Fully controlled, customizable local semantic firewalls. |
A Phased Architecture Roadmap for Enterprise Rollouts
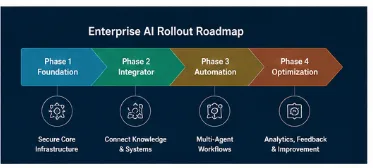
To guarantee system stability and secure user adoption, we advise our enterprise clients to scale their custom assistant platforms through three methodical development phases:
-
Phase 1 (The Read-Only Assistant): Build and deploy a secure RAG database index first. Allow employees to query internal files, wikis, and policies safely. This streamlines information lookup across your departments, saving hundreds of administrative hours. For a deeper look at designing these workflows, see our operational framework: AI Chatbots for Business: Are They Actually Worth It in 2026?.
-
Phase 2 (The Interactive Integrator): Connect your orchestration layer to secure, private database webhooks. Enable your assistant to actively update CRM profiles, generate localized reports, and schedule internal calendars. Explore how we map these custom workflows in our Velocity CRM System Case Study.
-
Phase 3 (The Multi-Agent Assembly Line): Transition from a single-assistant framework to a complex, automated network of specialized autonomous multi-agent systems that collaborate to manage complete operations (such as end-to-end accounting or compliance checks) without requiring human intervention.
Standardizing Enterprise Integrations with MCP
As organizations connect AI assistants to increasing numbers of enterprise systems, integration complexity quickly becomes a challenge.
The Model Context Protocol (MCP) is emerging as a standardized framework that allows AI systems to securely communicate with databases, APIs, CRM platforms, ERP systems, and internal business applications.
Rather than building and maintaining custom integrations for every application, MCP provides a consistent interface between AI systems and enterprise tools.
This simplifies security auditing, improves maintainability, and enables organizations to scale AI-driven workflows more efficiently.
For a deeper technical breakdown, read The Standardizing Core of Agentic AI: Model Context Protocol (MCP) Explained.
Secure Your Proprietary Advantage with Custom Architectures
Designing, hosting, and safeguarding a private AI framework that securely references your internal data stores requires deep software engineering expertise, reliable cloud orchestrations, and proven data-level security. At TechMamba, we engineer isolated, high-performance private assistant systems built specifically to protect your company's intellectual property while systematically eliminating administrative overhead.