Executive Summary
If you’ve spent any time exploring artificial intelligence for your business, you’ve likely hit a frustrating roadblock: large language models (LLMs) are incredibly smart, but they are also prone to confident guesswork and completely blind to your company’s internal data. Standalone models excel at general tasks but fail when required to recall precise, isolated enterprise information. According to Gartner, by 2027, over 75% of enterprises will deploy specialized retrieval systems to ground generative AI outputs, shifting away from standalone models to avoid operational liabilities and compliance risks.
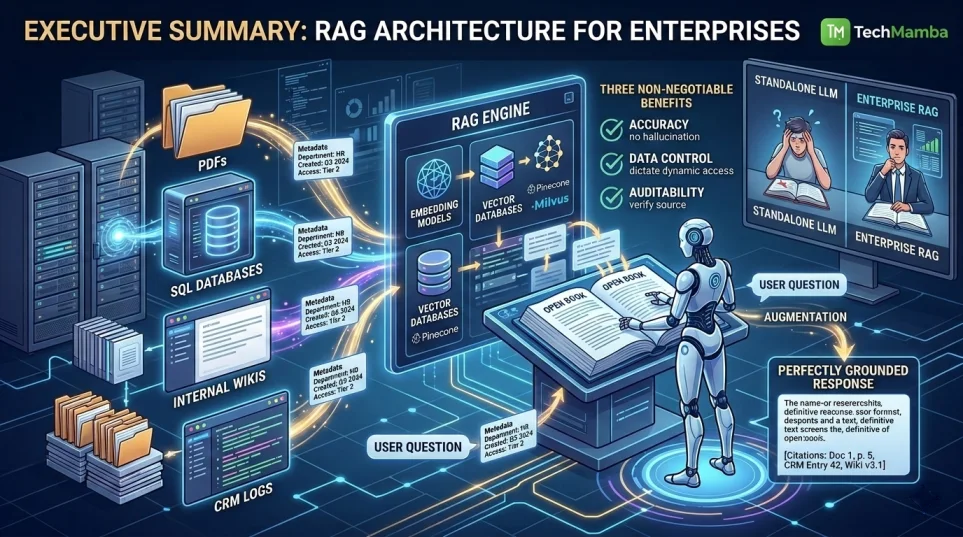
Retrieval-Augmented Generation (RAG) fixes this structural gap. Instead of forcing an LLM to rely purely on what it memorized during its training phase, a RAG architecture transforms it into an open-book researcher. When a user asks a question, the system searches your secure company databases, pulls up the exact document fragments needed, and hands them to the LLM to write a perfectly grounded, factual response.
For enterprises, RAG delivers three non-negotiable benefits: accuracy (no more hallucinated facts), data control (you dictate dynamic access permissions), and auditability (every answer points back to a verified source document). In 2026, RAG is no longer an experimental setup; it is the fundamental infrastructure powering customer support, legal compliance bots, and autonomous workflows. To transition from raw data silos to a fully production-hardened solution, enterprises partner with dedicated RAG Development Services to map out scalable pipeline blueprints.
What Is RAG Architecture?
The Core Concept: Moving from "Closed Book" to "Open Book"
Think of a standalone LLM as a student taking a closed-book exam. They might get an A- on general knowledge, but they will completely blank—or worse, make things up—when asked about your company's proprietary Q3 compliance policies.
A RAG architecture turns that exam into an open-book test. The engineering workflow follows a continuous, secure loop:
-
Data Ingestion: Your company files (PDFs, CRM logs, internal wikis, SQL databases) are securely parsed, cleaned of structural noise, and converted into mathematical indices.
-
Retrieval: A user asks a question, and the system instantly searches your data repositories to pull out the most contextually relevant paragraphs.
-
Augmentation: The system bundles the user’s original question together with those raw text snippets, forming a data-backed prompt.
-
Generation: The LLM reads the provided context and generates a precise, reliable answer solely from that data.
┌────────────────────────────────────────────────────────┐
│ User Prompt │
└───────────────────────────┬────────────────────────────┘
▼
┌────────────────────────────────────────────────────────┐
│ Retrieval Engine (Smart Search) │
└───────────────────────────┬────────────────────────────┘
▼
┌────────────────────────────────────────────────────────┐
│ Pulls Hyper-Relevant Text Chunks │
└───────────────────────────┬────────────────────────────┘
▼
┌────────────────────────────────────────────────────────┐
│ Context + Prompt Augmented Bundle │
└───────────────────────────┬────────────────────────────┘
▼
┌────────────────────────────────────────────────────────┐
│ LLM Generates Grounded Answer │
└────────────────────────────────────────────────────────┘
Why Raw LLMs Fail Enterprise Standards
Deploying a vanilla LLM in an enterprise setting introduces immense operational vulnerabilities. Research by McKinsey highlights that data inaccuracy and intellectual property leaks remain the top two corporate risks holding back generative AI adoption across knowledge-heavy industries. A structured RAG pipeline directly mitigates these vulnerabilities:
| Evaluation Vector | Standalone LLM | Enterprise RAG System |
| Hallucination Risk | High. Models prefer looking smart over saying "I don't know." | Low. The model is strictly bound to your provided documents. |
| Knowledge Currency | Frozen at its training cutoff date. | Real-time. Accesses current live data instantly. |
| Data Privacy | Cannot securely parse internal files dynamically. | Direct, secure integrations with CRMs, ERPs, and cloud drives. |
| Audit Trail | None. You must trust the output without verification. | Clear citations showing exactly which document, section, and page gave the answer. |
Core Components of an Enterprise RAG Stack
Building an enterprise-ready RAG system requires connecting seven modular layers. Engineering these layers effectively determines whether the application feels reliable, secure, fast, and affordable to operate.
┌─────────────────────────────────────────────────────────┐
│ 1. Application Layer │
└───────────────────────────┬─────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────┐
│ 2. API Gateway │
└───────────────────────────┬─────────────────────────────┘
▼
┌─────────────────────────────────────────────────────────┐
│ 6. Retrieval Engine │
│ ┌───────────────────────┴───────────────────────────┐ │
│ ▼ ▼ │
│ [3. Embedding Models] [5. Doc Storage]│
│ │ │ │
│ ▼ │ │
│ [4. Vector Databases] │ │
└───────────────────────────┬──────────────────────────┘ │
▼ │
┌─────────────────────────────────────────────────────────┐
│ 7. LLM Generation Layer │
└─────────────────────────────────────────────────────────┘
1. The Application Layer
This is your user interface. Whether it’s an embedded sidebar inside Salesforce, a Microsoft Teams integration, or a custom administrative dashboard, this layer manages user identities, validates inputs, and tracks session histories.
2. The API Gateway
The traffic cop of your AI architecture. It handles rate limiting, isolates corporate access privileges, balances requests across multiple LLM backends, and logs system telemetry for performance tracking. When building complex cross-departmental operations, this gateway often bridges your search indexes with broader AI Workflow Automation Services to trigger automated back-office operations based on the retrieved data.
3. Embedding Models
Computers don’t understand text; they understand vector geometry. Embedding models convert text chunks into high-dimensional numerical coordinates called vectors. These coordinates capture semantic meaning. For example, an embedding model knows that "revenue fell short" and "missed financial targets" are mathematically adjacent, even though they share zero identical keywords.
4. Vector Databases
Traditional databases look for exact text strings. Vector databases (such as Pinecone, Qdrant, or Milvus) store and index mathematical embeddings for low-latency similarity searches. They permit the system to run ultra-fast nearest-neighbor searches to match a user's question conceptually in milliseconds.
5. Document Storage
While the vector database handles spatial mathematics, you still need a home for the original files (PDFs, JSONs, docx formats). Cloud storage setups like AWS S3 or Azure Blob storage keep raw materials secure, allowing the system to surface the actual text excerpts and verify source links for end-users.
6. The Retrieval Engine
The brains behind the search. Instead of relying on just one query method, modern enterprise systems utilize Hybrid Retrieval. This blends traditional keyword search (BM25, great for precise part numbers, IDs, or legal codes) with semantic vector search (great for abstract conceptual questions) to maximize accuracy.
7. The LLM Generation Layer
The final step. This layer formats the prompt template, injects the retrieved context chunks, controls parameters like "temperature" (how creative or rigid the model behaves), and routes the package to foundation models like GPT-4o, Claude 3.5 Sonnet, or privately hosted Llama 3 instances.
The RAG Pipeline: Ingestion vs. Querying
A production-grade RAG setup operates in two distinct modes: Offline Ingestion (preparing your corporate data) and Online Querying (answering user questions in real-time).

Phase 1: The Offline Query Pipeline
Before your AI can read your internal data, you must transform it into structured, referenceable components:
-
Document Parsing: The pipeline extracts text from scanned PDFs, Word files, or internal wikis, systematically stripping out noisy formatting like page breaks, repetitive footers, and corrupted headers.
-
Intelligent Chunking: You cannot pass a 300-page manual to an LLM for a simple answer. The ingestion engine slices documents into small, logical paragraphs called "chunks" (usually 200 to 500 words). Crucially, it attaches metadata—such as document ownership, creation date, and organizational access tiers—to every chunk.
-
Indexing: These chunks pass through an embedding model and are saved into your vector database, building the indexed catalog for future search execution.
Phase 2: The Online Query Pipeline
When a user submits a question, the online stack springs to life in milliseconds:
-
Vectorizing the Query: The question is converted into an embedding using the identical model used during data ingestion.
-
Similarity Search & Filtering: The vector database identifies the top 20 text chunks that are mathematically closest to the question, applying strict metadata filters to match the user's corporate security access.
-
Cross-Encoder Reranking: A secondary machine learning model (a Re-ranker) re-scores those top 20 chunks to evaluate their actual logical relevance, filtering out noise and keeping only the absolute best 3 to 5 chunks.
-
Synthesis: The system constructs the prompt, embedding the query and verified chunks together, and sends it to the LLM to write a natural language response.
Real-World Enterprise Client Examples
Case Study 1: Resolving Information Silos for a Global Logistics Provider
The Challenge: A multinational logistics firm with over 45,000 employees struggled with fragmented operational files. Customer service and internal dispatch teams spent thousands of hours searching through 15,000 legacy PDFs detailing regional shipping laws, compliance standards, and custom border codes.
The Solution: TechMamba engineered a centralized enterprise RAG architecture. By breaking down their document store into 300-token semantic chunks using a hybrid BM25 and vector search engine, we created a localized query assistant.
The Result: The company saw a 64% reduction in repetitive internal HR and operational support tickets within the first 90 days. Furthermore, employee onboarding speed increased by an average of three weeks because team members could query regional compliance data instantly.
Case Study 2: Automated Contract Review for a Professional Services Firm
The Challenge: A boutique advisory firm spent a significant portion of their senior analysts' time manually reviewing vendor contracts, looking for non-standard compliance clauses, indemnification risks, and service level agreement (SLA) mismatches.
The Solution: We implemented a specialized RAG pipeline utilizing recursive chunking strategies optimized specifically for legal prose. The system mapped out cross-document clauses and linked them to an internal legal playbook index.
The Result: Contract auditing times dropped by 78%. Analysts shifted from reading contracts from scratch to reviewing automatically generated risk summaries that cited the exact page and paragraph numbers for audit validation.
Advanced RAG Patterns: Moving Towards Autonomous AI Agents
Simple RAG setups work well for straightforward Q&A, but real enterprise environments demand systems capable of handling multi-step reasoning and dynamic tool execution.
1. RAG with Memory
Standard foundational LLMs have no conversation memory; they forget historical inputs the moment a new one arrives. By implementing a dedicated session-memory layer, the RAG system retains the conversation's context. This allows users to ask multi-turn, contextual questions (e.g., "Can you locate our European remote work policy?" followed by "Great, now draft an announcement email based on the travel allowances listed in Section 4").
2. Branched RAG (Query Decomposition)
When a user asks a multi-layered question like, "How did our Q3 European sales compare to our Asian market performance, and what caused the gap?", a basic RAG system will fail. It searches for a single document that answers everything.
Branched RAG uses an LLM to split a complex query into separate sub-questions:
-
Sub-query 1: Search for Q3 European sales reports.
-
Sub-query 2: Search for Q3 Asian market data.
-
The system executes parallel retrieval loops, merges the documentation, and passes the combined findings to the LLM for unified synthesis.
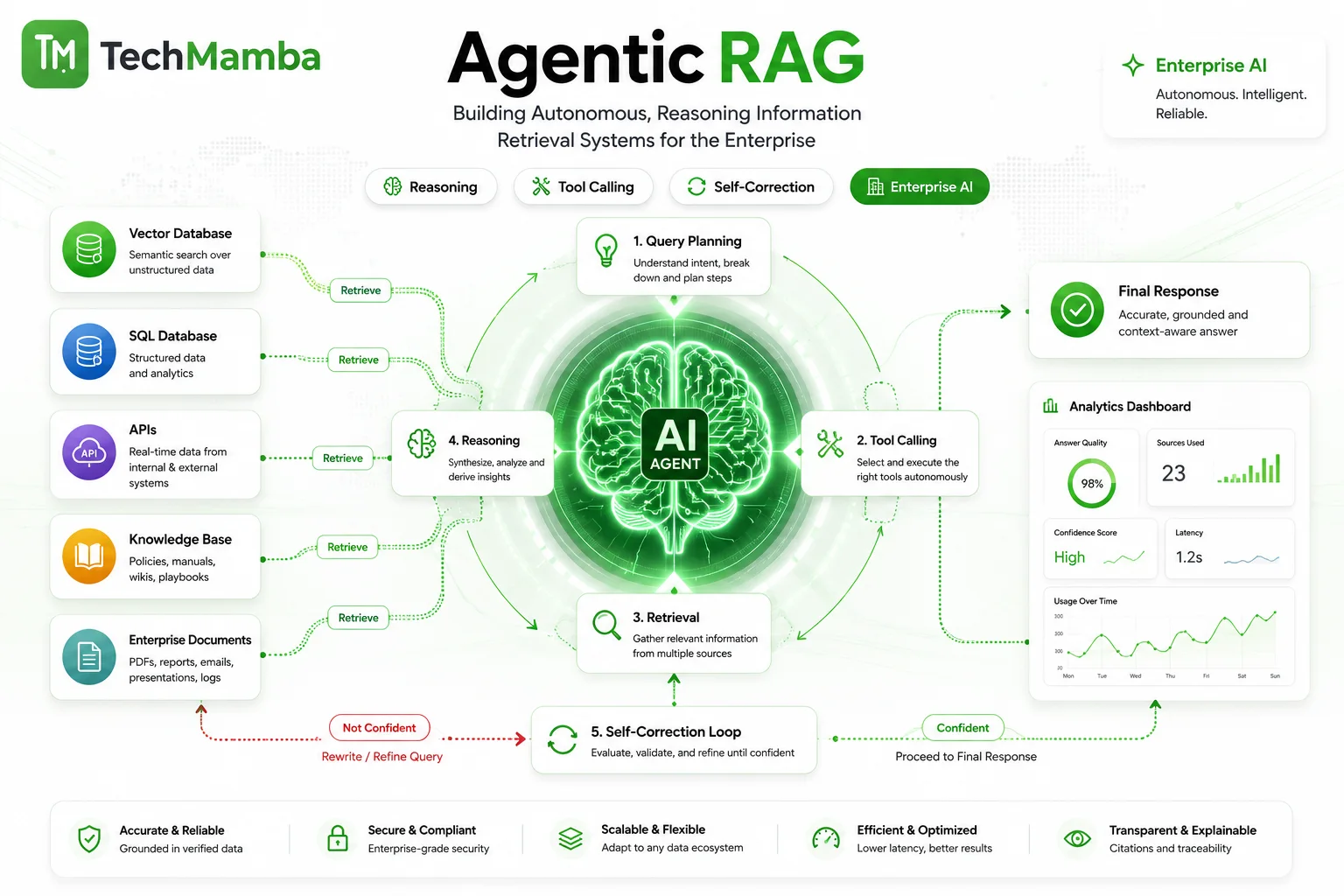
3. Agentic RAG
The gold standard of enterprise AI architecture. Instead of following a rigid, linear search pipeline, Agentic RAG turns the LLM into an autonomous decision-making orchestrator equipped with a suite of "tools". Enterprises looking to implement these responsive environments work closely with AI Agent Development Services to map out robust reasoning, tool-calling, and validation frameworks.
An Agentic RAG system doesn't give up if the first database search yields nothing. It evaluates the quality of the retrieved chunks, decides whether it needs to query an alternative SQL database, executes a secure Python script to analyze statistical trends, or routes a call to an external web API to fetch real-time information before finalizing its response.
Architectural Deep Dive: RAG vs. Fine-Tuning vs. AI Agents
Choosing the correct architecture depends entirely on whether your project goals require access to static style adjustments, dynamic knowledge management, or autonomous action execution.
| Architectural Pattern | Core Function | Primary Benefit | Best Use Cases |
| RAG Systems |
Links standard foundation LLMs to dynamic external knowledge repositories. |
Zero-hallucination factual precision with full source traceability and instant data updates. | Corporate policy search engines, customer support bots, and compliance validation. |
| Fine-Tuning | Adapts a base model on specialized text corpora to adjust its underlying neural weights. | Perfect alignment with specialized brand voices, niche syntax, and structural formatting rules. | Specialized programming code generation, medical dictation, and formatting conversion. |
| AI Agents |
Utilizes an LLM as an orchestrator to invoke third-party tools, APIs, and background scripts. |
Executes end-to-end multi-step reasoning and loops autonomously to fulfill actions. |
Automated systems triage, strategic financial forecasting, and active platform integration. |
Expert Quotes on RAG Implementations
"The mistake we see most technical teams make when building enterprise RAG is treating it purely as an AI problem. It isn't. RAG is 80% data engineering and infrastructure optimization. If your document chunking strategy doesn't respect the underlying data architecture, the most powerful model in the world will still give you subpar answers."
— Senior AI Solutions Architect, TechMamba Engineering
Technical Best Practices for Production
If you want your RAG system to maintain enterprise-grade reliability, avoid treating it like a plug-and-play tool. It requires rigorous, data-centric tuning.
Data Ingestion Strategy
-
Source Data Hygiene: If your internal SharePoint drive has five conflicting versions of a travel expense policy dating from 2021 to 2026, your AI will inevitably retrieve and cite outdated terms. Clean and archive old source files before building an index.
-
Enforce Metadata Filters: Tag document chunks with explicit structural categories (e.g.,
Department: HR,Region: APAC,Security_Clearance: Tier_2). This allows you to programmatically prevent a standard user from accidentally retrieving sensitive executive salary records during a vector search.
Selecting Your Text Chunking Strategy
| Document Type | Optimal Chunking Strategy | Target Size Boundary |
| Technical Manuals / API Codebases | Semantic Chunking (split explicitly by function, code blocks, and markdown headers) | 300–500 tokens |
| Legal Agreements & Vendor Contracts | Recursive Structural Chunking (split cleanly by numbered clauses and sub-sections) | 200–400 tokens |
| Customer Support Logs & Chat Histories | Fixed-size sliding windows accompanied by a 20-30% paragraph overlap | 150–300 tokens |
Getting Started: An Enterprise Implementation Roadmap
Ready to build? Avoid trying to launch an all-encompassing corporate platform overnight. Instead, scale through an iterative pipeline. For organizations mapping out infrastructure boundaries, consulting with specialized LLM Application Development Services can accelerate data formatting, framework selection, and safety guardrail timelines.
[Weeks 1-2: Use Case & Data Blueprinting]
│
▼
[Weeks 3-4: Prototyping & Hybrid Search Setup]
│
▼
[Weeks 5-6: Red-Teaming, Reranking & Evaluation]
│
▼
[Weeks 7+: Enterprise Scaling & Production Hardening]
Week 1–2: Blueprinting & Use-Case Selection
Isolate a single, high-value problem area with a manageable data footprint—such as an internal IT service desk assistant or an enterprise procurement policy finder. Ensure your data sources are mapped out and clean.
Week 3–4: Prototyping
Leverage modern application orchestration frameworks like LangChain or LlamaIndex alongside a resilient vector database like Pinecone or Qdrant. Ingest a representative subset of your target documentation (roughly 200–500 pages) and construct a baseline RAG pipeline.
Week 5–6: Red-Teaming & Evaluation
Put the prototype in front of your subject matter experts. Intentionally try to break the system with ambiguous questions, trick phrasing, and queries designed to induce hallucinations. Use this automated and human feedback to optimize your text chunking parameters, update system prompts, and refine your hybrid search weights.
Week 7+: Scaling & Production Hardening
Migrate your indexing pipelines to enterprise-grade, distributed vector infrastructure. Connect your corporate Single Sign-On (SSO) systems to enforce document-level access tokens, spin up real-time monitoring software to watch system latency, and roll out production access to teams. Navigating these custom code integrations and data-layer optimizations requires the steady execution found in Custom Software Development Services.
Conclusion
RAG architecture is the foundational framework for enterprise generative AI. By merging raw linguistic capabilities with isolated corporate databases, businesses can confidently deploy production-grade tools that eliminate traditional security risks, hallucinations, and outdated information.
Whether you are launching an autonomous compliance agent, an internal technical helper, or a customer support engine, success boils down to data cleanliness, deliberate chunking logic, and objective performance monitoring. Start with a tightly scoped prototype, validate your retrieval precision, and scale out to transform how your enterprise puts its organizational knowledge to work.
Need a production-ready RAG system?
TechMamba helps businesses build custom, secure, and production-hardened AI solutions. Our engineering team designs architecture tailormade for your proprietary data sources, complete with strict enterprise-grade security and zero-hallucination guardrails.
TechMamba helps businesses build:
-
Internal Knowledge Assistants: Turn scattered corporate PDFs, wikis, and legacy drives into a secure conversational index.
-
Enterprise Search Systems: Deploy hybrid, cross-department semantic search infrastructure optimized for high-volume querying.
-
AI Support Agents: Build real-time, multi-turn support assistants with integrated conversation memory systems.
-
Agentic AI Workflows: Orchestrate advanced autonomous networks capable of calling APIs, running background scripts, and self-correcting errors.
Talk to our AI engineering team today to scope your enterprise RAG pipeline.