
Your engineering team successfully launched a custom multi-agent workflow. The application has achieved strong organic user adoption, but your monthly cloud GPU hosting bills are scaling exponentially, and concurrent user surges are driving API response latency past ten seconds.
Welcome to the production bottleneck of enterprise AI.
In 2026, the primary operational challenge is no longer about proving a model can generate a correct response. It is about inference optimization—maintaining sub-second, real-time response times while keeping variable API token overhead under strict budget parameters. When deploying large language models (LLMs) at scale, naive implementation choices can lead to a severe financial "context tax" and compute bottlenecks that destroy your application's operating margins.
To scale successfully, software architects must look past generic model provider APIs. You need a dedicated, infrastructure-level strategy to manage model memory footprints, cache redundant context, and run high-efficiency serving frameworks.
Below is an engineering-focused guide to LLM inference serving, modeling Key-Value (KV) cache memory, and optimizing your production GPU runtime budgets.
What Is LLM Inference Optimization?
LLM inference optimization is the practice of refining the serving layer of large language models to maximize transaction throughput, minimize response latency (Time-to-First-Token), and reduce token consumption costs. It combines model compression techniques (like quantization), dynamic memory management (like PagedAttention), context caching, and highly parallelized serving frameworks to run AI workloads cost-effectively at scale.
The Three Core Pillars of LLM Inference Optimization
Optimizing enterprise LLM deployments requires balancing architectural tradeoffs across three distinct performance layers:
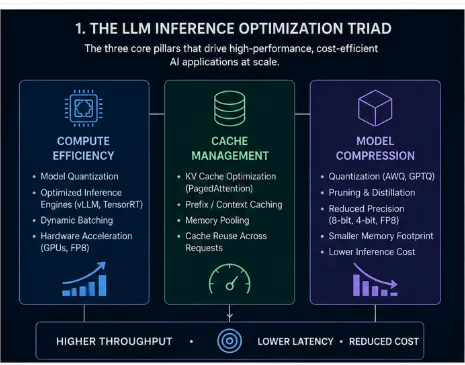
Figure 1. The LLM Inference Optimization Triad. Compute Efficiency, Cache Management, and Model Compression work together to maximize serving throughput while minimizing latency and hardware overhead.
Enterprise Inference Optimization in Practice
Optimizing your model runtime is not a generic task; it must align directly with the structural requirements of your target workloads:
-
High-Volume SaaS Platforms leverage prompt caching to bypass redundant database lookups. If thousands of users query the same technical repositories, caching the vectorized system instructions cuts duplicate processing overhead. See how custom software architecture protects your scaling margins in our comprehensive guide on Custom Software Development vs SaaS: When Businesses Should Build Instead of Buy.
-
Customer Service Autonomies optimize Time-to-First-Token (TTFT) metrics using model quantization. Dropping weights from 16-bit to 4-bit precision ensures your agents respond under 400ms, keeping conversational engagement exceptionally high. To see how these latency optimizations directly correlate with brand loyalty, check out our analysis on How AI-Powered Customer Support Is Reducing Costs and Improving UX.
-
Financial Trading Desks implement highly parallelized microservices to parse thousands of incoming market documents asynchronously, preventing request queue blockages during peak market hours.
-
Sovereign Private Deployments utilize optimized Small Language Models (SLMs) hosted on dedicated local GPUs, entirely eliminating third-party API transaction limits and ensuring 100% data residency. For a deep dive into self-hosted architecture design, consult our deployment blueprint on Building a Private AI Assistant: Architecture, Security, and Enterprise Best Practices.
Designing a High-Throughput Serving Architecture
Standard model loaders (like basic Hugging Face pipeline setups) fail under production workloads because they do not manage GPU memory dynamically. The primary memory bottleneck during LLM generation is the Key-Value (KV) Cache, which stores attention keys and values for past tokens to prevent redundant calculations during auto-regressive decoding.
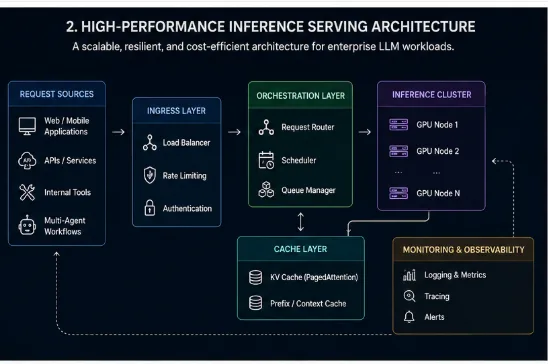
Figure 2. High-Performance Inference Serving Architecture. By separating system orchestration from compute-bound GPU serving clusters, we eliminate bottleneck queues and scale throughput.
By leveraging advanced memory management and asynchronous queueing, your engineering team can handle high concurrent volume without risking out-of-memory (OOM) server crashes.
The Role of PagedAttention and vLLM
In standard serving environments, KV cache memory is allocated statically, causing up to 60% of GPU memory to be wasted due to overallocation and fragmentation.
To solve this, modern serving engines (such as vLLM and TensorRT-LLM) implement PagedAttention. This technique partitions the KV cache into small, non-contiguous physical memory blocks, managing them exactly like virtual memory tables in operating systems. This completely eliminates memory fragmentation, allowing you to run up to 4x more concurrent queries on the same GPU cluster.
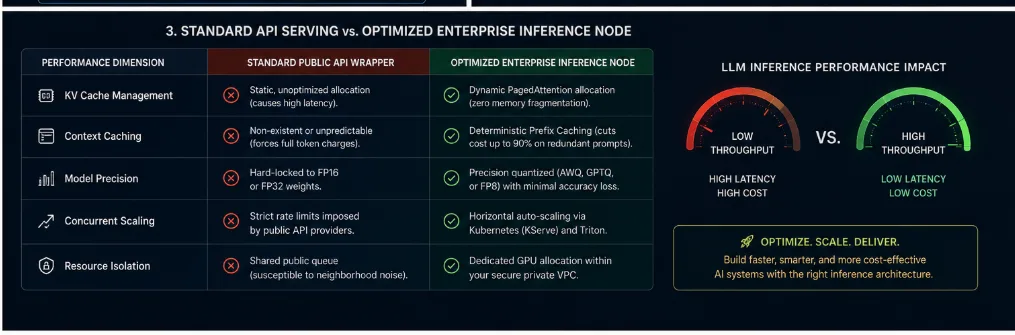
Technical Comparison: Standard API Serving vs. Hardened Optimization Node
Tooling and Optimization Best Practices
To maximize hardware throughput and keep inference costs low, enforce these three technical standards:
1. Implement Quantization (AWQ, GPTQ, or FP8)
Never host raw, uncompressed 16-bit models in production. Quantization techniques compress model parameters from 16-bit to 8-bit ($FP8$) or 4-bit ($AWQ$) representations. This reduces the model's memory footprint by up to 75%, allowing you to fit larger models on cheaper hardware while maintaining 99%+ of baseline accuracy.
2. Standardize on Open Standards (Triton & vLLM)
Deploy your quantized models within high-performance serving frameworks. Triton Inference Server paired with a vLLM engine provides out-of-the-box dynamic batching, concurrent model execution, and native support for GPUs across multiple cloud vendors.
3. Implement Context/Prefix Caching
In systems utilizing RAG Architecture or long, multi-step Agentic Retrieval-Augmented Generation (RAG) workflows, system instructions and document context blocks remain identical across hundreds of sequential requests. Enabling Automatic Prefix Caching allows the serving engine to bypass calculating attention states for identical text blocks, reducing latency and slashing input processing costs.
The Ultimate Convergence: Observability, Governance, and Performance
Systems performance is structurally linked to security and operations:
While Enterprise AI Security in 2026: Protecting LLMs, Data, and Business Workflows secures your endpoints, and AI Governance Explained: Building Responsible Enterprise AI Systems in 2026 audits model outputs for safety, AI Observability Explained: Monitoring LLMs and Multi-Agent Systems in Production tracks real-time token telemetry to trigger auto-scaling rules.
Integrating continuous telemetry with an optimized inference layer ensures that your multi-agent networks scale efficiently, stay secure under load, and operate within strict budgetary guardrails.
Expert Opinion: What Most Developers Get Wrong
A common mistake is trying to solve latency and cost issues by simply switching to a smaller model.
While moving from a 70B model to an 8B model will instantly lower your costs, it also degrades the reasoning quality of your system. Instead of sacrificing intelligence, focus on optimizing your Prompt-to-Token Ratio.
By compressing long prompts, utilizing prefix caching, implementing Grouped-Query Attention models, and using strict JSON schemas to prevent excessive, wordy outputs, you can routinely reduce operational costs by 50% to 70% while preserving the high reasoning capacity your workflows demand.
Optimize Your Production Infrastructure with TechMamba
Scaling enterprise AI applications while maintaining low latencies and stable operational margins requires deep, proven systems engineering. At TechMamba, we specialize in building highly optimized Private AI Assistant networks, highly performant RAG engines, and automated horizontal scaling pipelines designed to protect your bottom line.